HandPose
Single Hand Keypoints Detector
RUN
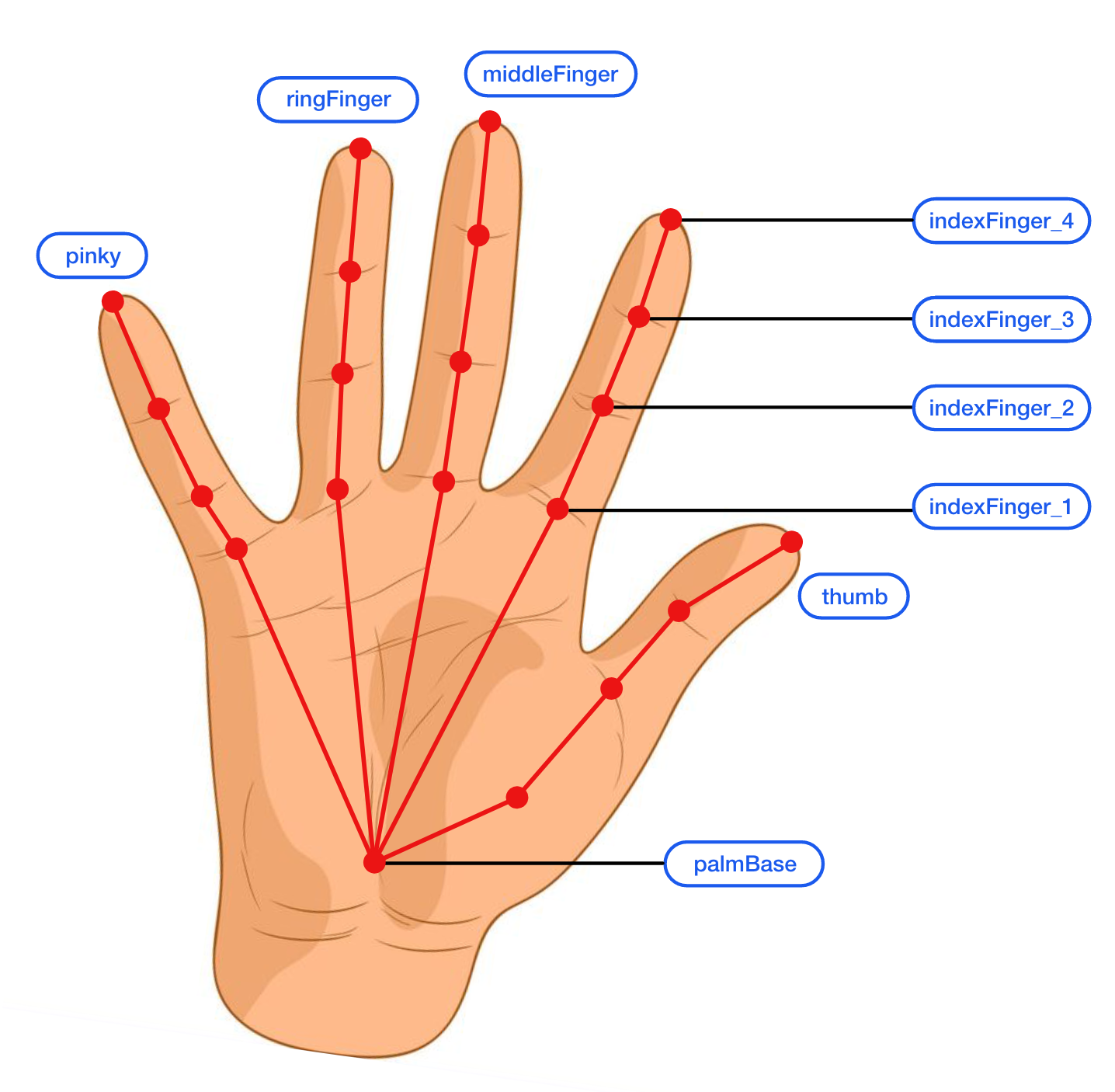
This module detects key hand points in hand figures using HandPose. The model works by first predicting whether a frame of a video recording contains a hand. If so, the model outputs a confidence score and a series of key points for the hand. The confidence score represents the probability that the hand has been correctly detected. It ranges from a value of 0 to 1, where 1 represents an exact detection. There are a total of 21 key points, which represent the location of each finger joint and the palm. A key point’s position represents the coordinates of the point in a video frame and is expressed as x, y, and z values.
The data is exported as a CSV file structured as follows:
| frame | handInViewConfidence | indexFinger_1_x | indexFinger_1_y | indexFinger_1_z | indexFinger_2_x | thumb_4_z | palmBase_x | palmBase_y | palmBase_z |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.986333966 | 322.4174449 | 168.304389 | -14.46016312 | 321.3518461 | -32.55603409 | 287.714139 | 272.9273902 | -0.00182613 |
| 1 | 0.986326456 | 322.4671148 | 166.8973452 | -14.31898689 | 320.9870967 | -33.10225296 | 287.6607924 | 271.9008103 | -0.001728684 |
| 2 | 0.986034989 | 321.2713459 | 167.3608348 | -13.81084251 | 320.5034114 | -32.29040146 | 286.5937991 | 272.8722047 | -0.001779698 |
The frame column represents the frame number in the video and the handInViewConfidence represents the detected hand’s confidence score in that frame. The rest of the columns are represented as [finger]_[joint]_[axis], except for the last three columns which are for the palm key points and are represented as palmBase_[axis]. So, for example, the indexFinger_1_x column represents the x coordinate of the first joint in the hand’s index finger. This is further illustrated in the figure below.
For more details on HandPose, refer to Google AI’s blogpost