Coco SSD Object Detector
Object Detection
RUN
Background
Object detection - the task of locating one or more objects in an image, drawing bounding boxes around them, and predicting the class of the objects - has been a core challenge in computer vision. The TensorFlow Object Detection API is an open source framework built on top of TensorFlow that makes it easy to construct, train and deploy object detection models.
This framework provides support for several object detection architectures such as SSD (Single Shot Detector) and Faster R-CNN (Faster Region-based Convolutional Neural Network), as well as feature extractors like MobileNet and Inception. The variety in architectures and extractors provides lots of options but deciding on which one to use depends on the use-case - what accuracy and speed is needed.
The multimodal toolkit contains an implementation of real time object detection using the COCO SSD model from tensorflow. The application takes in a video (either through webcam or uploaded) as an input and subsequently identifies all the objects present in each frame and returns their locations, class and confidence score.

Process
The pre-trained COCO-SSD model is on the fast-but-less-accurate side of the spectrum of all tensorflow architectures, allowing it to be used in a browser.
COCO refers to the "Common Objects in Context" dataset, the data on which the model was trained on. This collection of images is mostly used for object detection, segmentation, and captioning, and it consists of over 200k labeled images belonging to one of 90 different categories, such as "person," "bus," "zebra," and "tennis racket." SSD, short for Single Shot Detector, is a neural network architecture made of a single feed-forward convolutional neural network that predicts the image's objects labels and their position during the same action. The counterpart of this "single-shot" characteristic is an architecture that uses a "proposal generator," a component whose purpose is to search for regions of interest within an image.
Once the regions of interests have been identified, the second step is to extract the visual features of these regions and determine which objects are present in them, a process known as "feature extraction." COCO-SSD default's feature extractor is lite_mobilenet_v2, an extractor based on the MobileNet architecture. In general, MobileNet is designed for low resources devices, such as mobile, single-board computers, e.g., Raspberry Pi, and even drones.
Results
To use the real time object detection function, simply select the ‘Real Time Object Detection’ option from the tools page. Once the page loads, ensure that the webcam is enabled and the function will automatically detect all the objects shown in the video frame that has been trained in the COCO-SSD model, and output information of each object found. Users can also record a video or upload a video and download data on the objects.
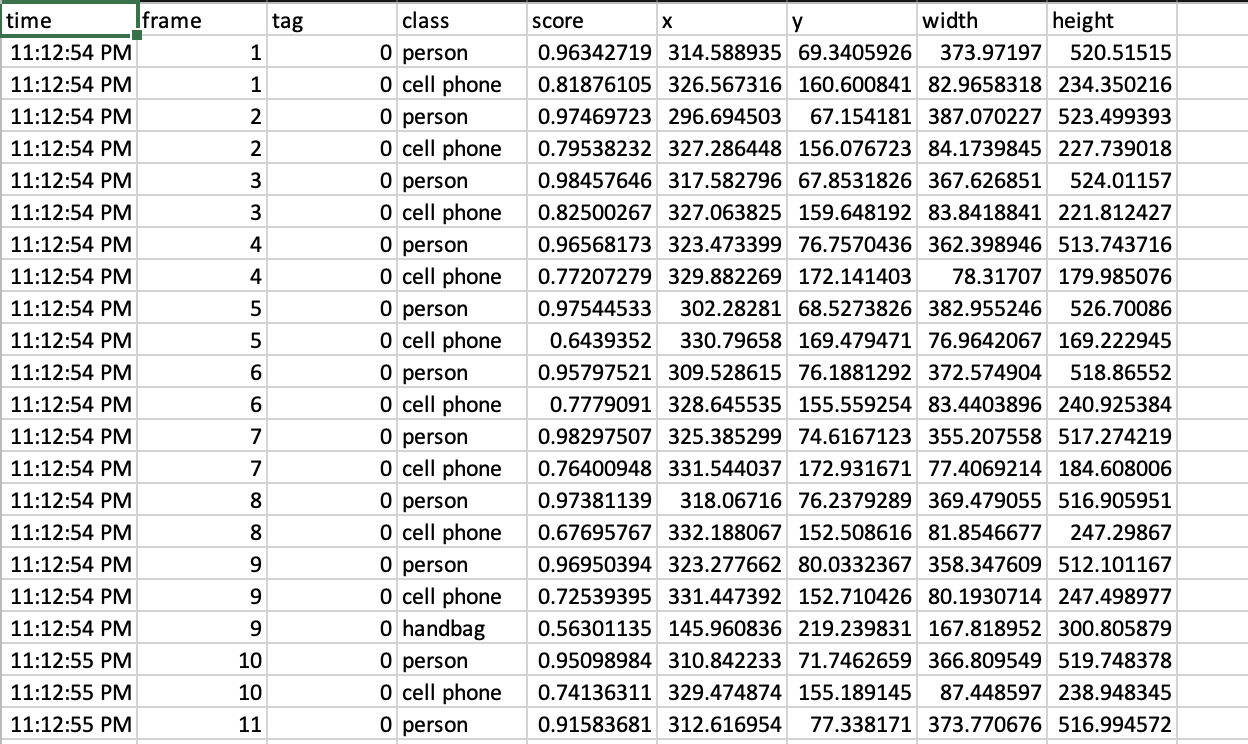
The final output for real time object detection is shown in an example below (see figure below). For each frame the model tracks, if the model finds one or more objects, it will return the class/category (person, couch, etc), statistics of the bounding box, and the confidence score of the object. We will then record the user's local time (for the webcam recording) or the video time (of the user uploaded video) when the frame was tracked, the number of the frame (since the beginning of the recording), the category/class and confidence score of the object, and the X & Y coordinates, width and height of the bounding box. Each line in the output file corresponds to one object in one frame. For frames where no objects are detected, we omit them in the final output.
References
- GitHub: https://github.com/juandes/tensorflowjs-objectdetection-tutorial
- Process: https://nanonets.com/blog/object-detection-tensorflow-js/
- Tensorflow API: https://github.com/tensorflow/models/blob/master/research/object_detection/README.md